Hilbert Modular Surfaces and Hilbert Modular Forms: The Basics
A Hilbert modular surface is a kind of Shimura variety (see Shimura Varieties), in a sense one of the next simplest after modular curves (although Shimura curves have lower dimension and Siegel modular threefolds have a simpler moduli interpretation). Aside from being a higher-dimensional analogue of modular curves, Hilbert modular surfaces possess interesting structure not present in modular curves. For example, Hilbert modular forms may contain embedded modular curves as codimension  subvarieties!
subvarieties!
We begin with the definition. Let 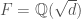 , where
, where 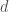 is a squarefree positive integer, i.e.
is a squarefree positive integer, i.e.  is a real quadratic field. We denote its ring of integers by
is a real quadratic field. We denote its ring of integers by 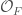 . The group
. The group 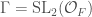 acts on the product
acts on the product  of two upper half-planes as follows:
of two upper half-planes as follows:

for 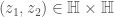 , where
, where 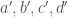 are the Galois conjugates of
are the Galois conjugates of 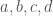 . If we then take the left quotient of
. If we then take the left quotient of 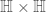 by this action of
by this action of 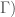 , we then end up with a complex analytic surface
, we then end up with a complex analytic surface 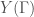 , which is non-compact. Just as the “open” modular curve constructed in The Moduli Space of Elliptic Curves parametrizes elliptic curves over
, which is non-compact. Just as the “open” modular curve constructed in The Moduli Space of Elliptic Curves parametrizes elliptic curves over  , the open modular surface which we have just constructed parametrizes abelian surfaces
, the open modular surface which we have just constructed parametrizes abelian surfaces  over with an extra “real multiplication” structure, which is an embedding of into their ring of endomorphisms
over with an extra “real multiplication” structure, which is an embedding of into their ring of endomorphisms 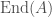 .
.
We may “compactify” the above construction by instead considering the quotient  (note that
(note that 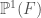 is also equipped with an action of
is also equipped with an action of 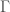 ), which adds a finite number (equal to the class number of ) of points called cusps. This compactification, which we denote
), which adds a finite number (equal to the class number of ) of points called cusps. This compactification, which we denote  , will be singular. However, by the theory developed by Heisuke Hironaka, there is a way to “resolve” the singularities, and by applying this theory we may obtain a smooth projective surface
, will be singular. However, by the theory developed by Heisuke Hironaka, there is a way to “resolve” the singularities, and by applying this theory we may obtain a smooth projective surface 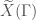 .
.
Hilbert modular surfaces are the natural home of Hilbert modular forms (although Hilbert modular forms live on Hilbert modular varieties, more generally, as we mention in the next paragraph). A Hilbert modular form of weight 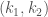 is a meromorphic function
is a meromorphic function  on such that, for
on such that, for 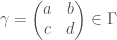 , we have
, we have

From the point of view of algebraic geometry, Hilbert modular forms can also be obtained as sections of certain sheaves on a Hilbert modular surface.
Before we continue our discussion of Hilbert modular surfaces, we note that all of the above constructions may be generalized by letting be a more general totally real field, instead of just a real quadratic field. This leads to the more general notion of a Hilbert modular variety, and of more general Hilbert modular forms. We also note that instead of , we could instead consider some nontrivial level structure  , where
, where  is some fractional ideal of . The group
is some fractional ideal of . The group 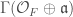 is defined to be the group of matrices of the form
is defined to be the group of matrices of the form 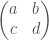 where
where 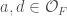 ,
,  , and
, and  .
.
A Whirlwind Introduction to Clifford Algebras and Spin Groups
We have so far described Hilbert modular surfaces and Hilbert modular forms in terms of the group 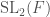 . However there is another way to describe them via the exceptional isomorphisms of spin groups (which are double covers of special orthogonal groups, see also Rotations in Three Dimensions) with other groups – In our case, we have the isomorphism
. However there is another way to describe them via the exceptional isomorphisms of spin groups (which are double covers of special orthogonal groups, see also Rotations in Three Dimensions) with other groups – In our case, we have the isomorphism 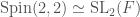 . Let us discuss first the general theory behind spin groups of signature
. Let us discuss first the general theory behind spin groups of signature  and their associated symmetric spaces, and then later we apply it to the specific case of Hilbert modular surfaces.
and their associated symmetric spaces, and then later we apply it to the specific case of Hilbert modular surfaces.
Let  be a pair consisting of a vector space
be a pair consisting of a vector space  over
over 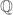 and a quadratic form
and a quadratic form  . The orthogonal group
. The orthogonal group  is the subgroup of the group of linear transformations of which preserve . The Clifford algebra
is the subgroup of the group of linear transformations of which preserve . The Clifford algebra 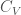 associated to is the quotient of the tensor algebra of by the relation, for all
associated to is the quotient of the tensor algebra of by the relation, for all 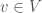 ,
,
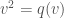
The Clifford algebra generalizes many familiar constructions such as the complex numbers (for  and
and  ) and Hamilton’s quaternions for
) and Hamilton’s quaternions for 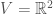 and
and  . Note that, unlike the complex numbers, more general Clifford algebras such as Hamilton’s quaternions have more than one type of “conjugation”. The first, which we shall call
. Note that, unlike the complex numbers, more general Clifford algebras such as Hamilton’s quaternions have more than one type of “conjugation”. The first, which we shall call 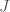 , is induced by negation of basis elements of . Another is given by cyclically permuting the tensor factors of an element so that
, is induced by negation of basis elements of . Another is given by cyclically permuting the tensor factors of an element so that 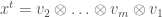 for
for  . This second conjugation allows us to define the Clifford norm:
. This second conjugation allows us to define the Clifford norm:

The even Clifford algebra  of is the subalgebra generated by elements which are a product of an even number of basis elements of . The odd part
of is the subalgebra generated by elements which are a product of an even number of basis elements of . The odd part 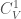 is similarly defined, and we have the decomposition
is similarly defined, and we have the decomposition  . The Clifford group is defined to be the set of all invertible elements
. The Clifford group is defined to be the set of all invertible elements  of the Clifford algebra such that
of the Clifford algebra such that 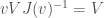 . The intersection of the even Clifford algebra and the Clifford group is called
. The intersection of the even Clifford algebra and the Clifford group is called  . The set of elements of whose Clifford norm is equal to is called
. The set of elements of whose Clifford norm is equal to is called 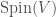 .
.
We now mention some facts about the special case when has dimension  that we will use later when we discuss Hilbert modular surfaces again. Let
that we will use later when we discuss Hilbert modular surfaces again. Let  be a basis of such that
be a basis of such that 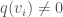 for all
for all  . Let
. Let  . The center
. The center 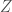 of the Clifford algebra associated to is then isomorphic to
of the Clifford algebra associated to is then isomorphic to 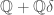 , and the even Clifford algebra admits the description
, and the even Clifford algebra admits the description
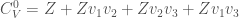
Fix an element  such that
such that 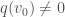 and for
and for 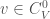 let
let 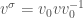 . We define the new vector space
. We define the new vector space  to be the set of all elements of such that the automorphism
to be the set of all elements of such that the automorphism 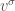 agrees with the conjugation
agrees with the conjugation 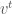 , and we equip with the quadratic form
, and we equip with the quadratic form 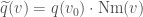 . It turns out that
. It turns out that 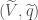 is isometric to , and the upshot is that we can now describe the action of an element
is isometric to , and the upshot is that we can now describe the action of an element 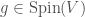 on an element
on an element  as follows:
as follows:
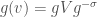 .
.
Symmetric Spaces for Orthogonal Groups of Signature (2,n): Three Descriptions
The upper-half plane is the “symmetric space” for the group 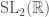 , and may be obtained as the quotient of by its locally compact subgroup
, and may be obtained as the quotient of by its locally compact subgroup 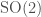 . We want to generalize this to the group , but it is often useful to have different descriptions of the symmetric space. We will discuss three different descriptions of the symmetric space on which acts, each one with its own advantages and disadvantages.
. We want to generalize this to the group , but it is often useful to have different descriptions of the symmetric space. We will discuss three different descriptions of the symmetric space on which acts, each one with its own advantages and disadvantages.
First we give the “Grassmannian model“. The Grassmannian parametrizes  -dimensional subspaces of a vector space. It is a generalization of projective space (which is the special case when
-dimensional subspaces of a vector space. It is a generalization of projective space (which is the special case when 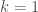 ). In our case, we want to parametrize
). In our case, we want to parametrize  -dimensional spaces of , with the additional condition that the quadratic form is positive definite on this space:
-dimensional spaces of , with the additional condition that the quadratic form is positive definite on this space:
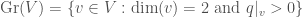
The group acts on 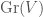 , and the stabilizer of an element
, and the stabilizer of an element 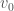 is a maximal compact subgroup
is a maximal compact subgroup  , which is isomorphic to
, which is isomorphic to 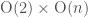 . Therefore we can see that
. Therefore we can see that 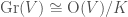 , and provides a realization of its associated symmetric space. However, in this model it is harder to see the complex analytic structure.
, and provides a realization of its associated symmetric space. However, in this model it is harder to see the complex analytic structure.
This problem can be remedied by considering the “projective model“. Let 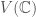 be the complexification of and define
be the complexification of and define
![\displaystyle \mathcal{K}=\lbrace[z]\in\mathbb{P}(V(\mathbb{C})):(z,z)=0,(z,\overline{z})>0\rbrace](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BK%7D%3D%5Clbrace%5Bz%5D%5Cin%5Cmathbb%7BP%7D%28V%28%5Cmathbb%7BC%7D%29%29%3A%28z%2Cz%29%3D0%2C%28z%2C%5Coverline%7Bz%7D%29%3E0%5Crbrace&bg=ffffff&fg=444444&s=0&c=20201002)
Now 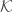 is an
is an  -dimensional complex manifold consisting of two connected components. We choose one of these components and denote it by
-dimensional complex manifold consisting of two connected components. We choose one of these components and denote it by 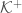 – this is our symmetric space. Although the complex analytic structure is easier to see in the projective model, it is hard to relate this model to well-known examples of symmetric spaces such as the upper half-plane (which is the case when
– this is our symmetric space. Although the complex analytic structure is easier to see in the projective model, it is hard to relate this model to well-known examples of symmetric spaces such as the upper half-plane (which is the case when  ).
).
Finally we consider the “tube domain model“. Let  be a nonzero isotropic vector in and let
be a nonzero isotropic vector in and let 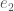 be another vector in such that
be another vector in such that 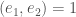 . We let
. We let 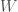 be the intersection of the orthogonal complements of and in , so that
be the intersection of the orthogonal complements of and in , so that
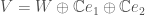
On the vector space , the restriction of the quadratic form has signature 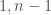 . We let
. We let 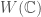 denote the complexification of and define
denote the complexification of and define

We can define a biholomorphic map between 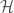 and by sending
and by sending  to
to ![[(z,1,-q(z)-q(e_{2}))]](https://s0.wp.com/latex.php?latex=%5B%28z%2C1%2C-q%28z%29-q%28e_%7B2%7D%29%29%5D&bg=ffffff&fg=444444&s=0&c=20201002) . We denote the preimage of by
. We denote the preimage of by  – the latter is analogous to the upper half-plane.
– the latter is analogous to the upper half-plane.
Heegner Divisors
Let us now consider smaller modular varieties embedded in other bigger modular varieties. Let 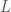 be a lattice in . The idea is that if we pick a vector
be a lattice in . The idea is that if we pick a vector 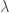 in the dual lattice
in the dual lattice 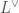 in , and consider the orthogonal complement of in , what we get is actually a vector space of signature
in , and consider the orthogonal complement of in , what we get is actually a vector space of signature 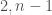 , to which we can once again apply the preceding constructions! Applied to the case of Hilbert modular surfaces, this explains the embedded modular curves. In symbols, we have
, to which we can once again apply the preceding constructions! Applied to the case of Hilbert modular surfaces, this explains the embedded modular curves. In symbols, we have
![\displaystyle H_{\lambda}=\lbrace [Z]\in\mathcal{K}^{+}:(Z,\lambda)=0\rbrace](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H_%7B%5Clambda%7D%3D%5Clbrace+%5BZ%5D%5Cin%5Cmathcal%7BK%7D%5E%7B%2B%7D%3A%28Z%2C%5Clambda%29%3D0%5Crbrace&bg=ffffff&fg=444444&s=0&c=20201002)
If we write 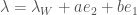 , then we can also describe
, then we can also describe 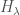 in the tube domain model as follows:
in the tube domain model as follows:
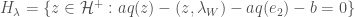
We can now define the Heegner divisor 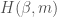 as the sum of all the where
as the sum of all the where 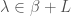 satisfies the condition that
satisfies the condition that 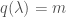 . We can further define the composite Heegner divisor
. We can further define the composite Heegner divisor 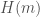 as half the sum of all Heegner divisors as
as half the sum of all Heegner divisors as 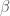 runs over
runs over 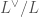 .
.
Back to Hilbert Modular Surfaces
We now go back to our setting of Hilbert modular surfaces and apply the above theory to the -dimensional vector space 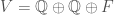 , equipped with the quadratic form
, equipped with the quadratic form  . We choose the following basis for :
. We choose the following basis for :
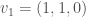
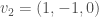
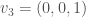
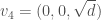
In this case the center of the Clifford algebra is isomorphic to , and the even Clifford algebra of is of the form  . Via the assignments
. Via the assignments

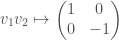
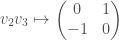
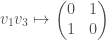
we have an isomorphism between and  . Furthermore, the Clifford norm on corresponds to the determinant on . All in all, this gives us an isomorphism between
. Furthermore, the Clifford norm on corresponds to the determinant on . All in all, this gives us an isomorphism between 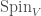 and . The theory we have discussed earlier provides us with the following vector space isomorphic to :
and . The theory we have discussed earlier provides us with the following vector space isomorphic to :
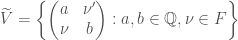
We also have a description of the lattices and as matrices inside as follows:
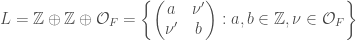
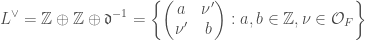
It turns out, just as we have 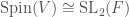 , we also have
, we also have 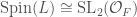 . In turn this gives us an isomorphism
. In turn this gives us an isomorphism 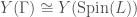 .
.
Now we apply the general theory of Heegner divisors. In the special case of Hilbert modular surfaces, the Heegner divisors 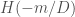 where
where  is the discriminant of are also known as Hirzebruch-Zagier divisors. They have the explicit description
is the discriminant of are also known as Hirzebruch-Zagier divisors. They have the explicit description

where the sum is over all  such that
such that 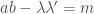 . As a special case,
. As a special case,  is the modular curve of level (i.e. the compactified moduli space of elliptic curves).
is the modular curve of level (i.e. the compactified moduli space of elliptic curves).
Borcherds Products and the Kudla Program: A Preview
Hirzebruch-Zagier divisors are related to certain Hilbert modular forms called Borcherds products, which arise as “theta lifts” (see also The Theta Correspondence) of weakly holomorphic modular forms (which are almost the same as modular forms, but the holomorphicity condition at the cusps is relaxed). Here “theta lifts” is in quotes because the liftings are somewhat different from what is described in The Theta Correspondence; for one, the integral is divergent and requires a “regularization” to get it to converge, and the lifting is multiplicative, which gives it an expression as an infinite product – hence the name “Borcherds products”.
The Hirzebruch-Zagier divisors, or more generally the Heegner divisors, or even more generally “special cycles” can also be put together in a certain way to form a generating series, which should form a “modular form valued in the Chow group”. This is part of what is known as the “Kudla program” which has applications for instance to conjectures on special values of L-functions (which generalize the Birch and Swinnerton-Dyer conjecture). These and other fascinating aspects of orthogonal and unitary Shimura varieties will hopefully be covered in future posts.
References:
Hilbert modular variety on Wikipedia
Hilbert modular form on Wikipedia
Hilbert modular forms and their applications by Jan Hendrik Bruinier
Hilbert Modular Surfaces by Gerard van der Geer
The 1-2-3 of Modular Forms by Jan Hendrik Bruinier, Gunter Harder, Gerard van der Geer, and Don Zagier
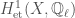 ). Cohomology with integral coefficients holds some information that gets lost when passing to rational coefficients; for instance, all the information about the torsion is lost. If we want to relate, say, torsion subgroups of different cohomologies to each other, we would need some sort of integral p-adic Hodge theory. In this post, we will discuss one approach to integral p-adic Hodge theory, called prismatic cohomology, developed by Bhargav Bhatt and Peter Scholze.
). Cohomology with integral coefficients holds some information that gets lost when passing to rational coefficients; for instance, all the information about the torsion is lost. If we want to relate, say, torsion subgroups of different cohomologies to each other, we would need some sort of integral p-adic Hodge theory. In this post, we will discuss one approach to integral p-adic Hodge theory, called prismatic cohomology, developed by Bhargav Bhatt and Peter Scholze. -rings. A
-rings. A  together with a map
together with a map 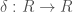 called a p-derivation, satisfying the following properties:
called a p-derivation, satisfying the following properties: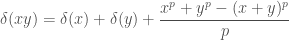
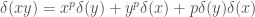
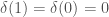
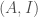 consisting of a
consisting of a 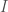 defining a Cartier divisor on
defining a Cartier divisor on 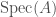 , such that
, such that 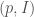 -complete (this means that for every
-complete (this means that for every 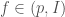 we have, considering
we have, considering 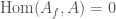 and
and 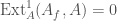 ) and
) and 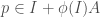 .
.![A=\mathbb{Z}_{p}[[u]]](https://s0.wp.com/latex.php?latex=A%3D%5Cmathbb%7BZ%7D_%7Bp%7D%5B%5Bu%5D%5D&bg=ffffff&fg=444444&s=0&c=20201002) and taking
and taking 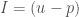 . Another important example that we will show up again later in this post is given by
. Another important example that we will show up again later in this post is given by 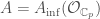 and
and 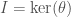 , where
, where 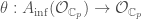 is the canonical map (see also
is the canonical map (see also 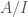 is an perfectoid ring. In fact, there is an equivalence of categories between perfect prisms and perfectoid rings, and one can go the other way via the
is an perfectoid ring. In fact, there is an equivalence of categories between perfect prisms and perfectoid rings, and one can go the other way via the 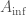 construction, i.e. given a perfectoid ring
construction, i.e. given a perfectoid ring 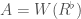 , and there is a canonical map
, and there is a canonical map 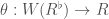 , and we set
, and we set 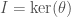 ; then the pair
; then the pair 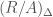 , is the category of prisms
, is the category of prisms 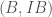 over
over 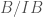 over
over 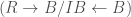 . We have functors
. We have functors  and
and  which send
which send  and
and 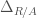 , to be
, to be 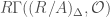 . As an example, in the special case that
. As an example, in the special case that 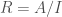 , then the prismatic cohomology
, then the prismatic cohomology  in
in  -modules instead), prismatic F-crystals (prismatic crystals
-modules instead), prismatic F-crystals (prismatic crystals 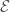 with an isomorphism
with an isomorphism ![\phi^{*}\mathcal{E}[1/I]\to\mathcal{E}[1/I]](https://s0.wp.com/latex.php?latex=%5Cphi%5E%7B%2A%7D%5Cmathcal%7BE%7D%5B1%2FI%5D%5Cto%5Cmathcal%7BE%7D%5B1%2FI%5D&bg=ffffff&fg=444444&s=0&c=20201002) ), and notions of crystals where instead of modules we consider complexes (perfect or
), and notions of crystals where instead of modules we consider complexes (perfect or 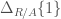 , which corresponds to the Tate twist in etale cohomology. The prismatic cohomology also comes with a filtration, called the Nygaard filtration. These structures are important for some of the applications of prismatic cohomology. For instance, the two notions just discussed allows us to give a definition of syntomic cohomology as follows:
, which corresponds to the Tate twist in etale cohomology. The prismatic cohomology also comes with a filtration, called the Nygaard filtration. These structures are important for some of the applications of prismatic cohomology. For instance, the two notions just discussed allows us to give a definition of syntomic cohomology as follows: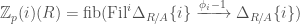
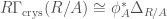
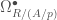 that computes the de Rham cohomology of
that computes the de Rham cohomology of 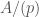 is related to
is related to  as follows:
as follows: 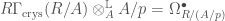
 (we call such an element
(we call such an element ![\displaystyle R\Gamma_{\mathrm{et}}(\mathrm{Spec}(R)[1/p],\mathbb{Z}/p^{n})\cong (\Delta_{R/A}[1/d]/p^{n})^{\phi=1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R%5CGamma_%7B%5Cmathrm%7Bet%7D%7D%28%5Cmathrm%7BSpec%7D%28R%29%5B1%2Fp%5D%2C%5Cmathbb%7BZ%7D%2Fp%5E%7Bn%7D%29%5Ccong+%28%5CDelta_%7BR%2FA%7D%5B1%2Fd%5D%2Fp%5E%7Bn%7D%29%5E%7B%5Cphi%3D1%7D&bg=ffffff&fg=444444&s=0&c=20201002)
 be a proper formal scheme over
be a proper formal scheme over  . Let
. Let 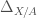 by gluing together the different
by gluing together the different 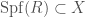 , and then use the comparison theorems previously mentioned to prove the following result:
, and then use the comparison theorems previously mentioned to prove the following result: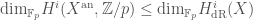
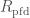 which is perfectoid, and such that for any other perfectoid ring
which is perfectoid, and such that for any other perfectoid ring  ,
, 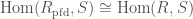 . As we just stated, a way to construct the perfectoidization is given by the perfected prismatic cohomology. Let
. As we just stated, a way to construct the perfectoidization is given by the perfected prismatic cohomology. Let 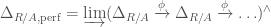
 . The pair
. The pair 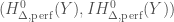 is a perfect prism, and the quotient
is a perfect prism, and the quotient 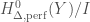 is a perfectoidization of
is a perfectoidization of 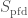 ).
).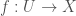 be an etale morphism. We may express this as the composition
be an etale morphism. We may express this as the composition 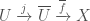 , where
, where  is finite. We may express
is finite. We may express 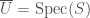 and
and 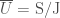 . Then we can define
. Then we can define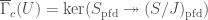
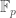 -algebra, then the functor which sends the sheaf
-algebra, then the functor which sends the sheaf 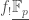 to
to 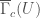 may be taken to be a Riemann-Hilbert functor, agreeing with previous constructions of Bhatt and Lurie. Inspired by this, in the more general case we can define
may be taken to be a Riemann-Hilbert functor, agreeing with previous constructions of Bhatt and Lurie. Inspired by this, in the more general case we can define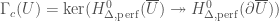
 is an
is an 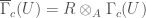 . For an etale morphism
. For an etale morphism 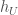 be the sheaf
be the sheaf 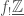 on
on 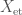 , where
, where 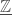 is the constant sheaf of
is the constant sheaf of  -coefficients. Sheaves of this form generate the category of abelian sheaves on
-coefficients. Sheaves of this form generate the category of abelian sheaves on ![R=\mathbb{Z}[x_{1},\ldots,x_{n}]](https://s0.wp.com/latex.php?latex=R%3D%5Cmathbb%7BZ%7D%5Bx_%7B1%7D%2C%5Cldots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) . Let
. Let  denote the integral closure of
denote the integral closure of  , the ring
, the ring 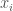 is a zero divisor of
is a zero divisor of 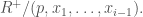 A “global” version of this theorem is mixed-characteristic Kodaira vanishing up to finite covers, also proved by Bhatt, and which has applications to the minimal model program in birational geometry.
A “global” version of this theorem is mixed-characteristic Kodaira vanishing up to finite covers, also proved by Bhatt, and which has applications to the minimal model program in birational geometry.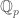 . The methods appear to differ from what has been discussed in this post, instead using a version of the methods developed by Peter Scholze in his work on p-adic Hodge theory for rigid analytic varieties (also very briefly mentioned in
. The methods appear to differ from what has been discussed in this post, instead using a version of the methods developed by Peter Scholze in his work on p-adic Hodge theory for rigid analytic varieties (also very briefly mentioned in 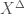 of a p-adic formal scheme
of a p-adic formal scheme 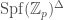 of
of 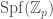 ). The prismatization
). The prismatization 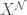 , the Nygaard filtered prismatization of
, the Nygaard filtered prismatization of 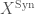 called the syntomification of
called the syntomification of 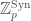 , upon inverting
, upon inverting 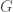 be such a finitely presented group, with generators
be such a finitely presented group, with generators  and relations
and relations  . Let us consider its
. Let us consider its 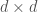 matrices
matrices  , with coefficients in
, with coefficients in  . Then we have to quotient out by the relations
. Then we have to quotient out by the relations  , each viewed as a relation on the matrices
, each viewed as a relation on the matrices  , and what we get is a stack.
, and what we get is a stack.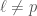 , i.e. our representations will be on
, i.e. our representations will be on 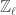 -algebra. Consider
-algebra. Consider  be its residue field. As a shorthand let us also denote
be its residue field. As a shorthand let us also denote  by
by 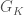 . Let us recall (see also
. Let us recall (see also 
 is called the inertia group. An extension of
is called the inertia group. An extension of 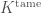 be the maximal tamely ramified extension of
be the maximal tamely ramified extension of  be the maximal unramified extension of
be the maximal unramified extension of  and let
and let  . We have an exact sequence
. We have an exact sequence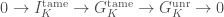
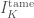 is called the tame inertia. It is a quotient of the inertia group
is called the tame inertia. It is a quotient of the inertia group  , called the wild inertia. The tame inertia
, called the wild inertia. The tame inertia 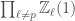 and is a pro-cyclic group.
and is a pro-cyclic group. be a generator of
be a generator of  be a lift of Frobenius in
be a lift of Frobenius in  . We consider the subgroup of
. We consider the subgroup of 


 is defined to be the limit
is defined to be the limit  , where
, where  is an open subgroup of
is an open subgroup of  is in turn defined to be the extension of the finitely presented group
is in turn defined to be the extension of the finitely presented group  , i.e.
, i.e. 
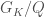 , and we have
, and we have 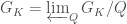 .
.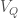 be the moduli stack of representations of the finitely presented group
be the moduli stack of representations of the finitely presented group  .
.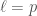 case is much more subtle. To properly construct the moduli stack of Galois representations for the
case is much more subtle. To properly construct the moduli stack of Galois representations for the 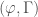 -modules, which will not discuss in this post, though hopefully we will be able to in some future post.
-modules, which will not discuss in this post, though hopefully we will be able to in some future post.  denote the Galois group of the maximal Galois extension of
denote the Galois group of the maximal Galois extension of  -algebra
-algebra  . The functor that assigns to such an
. The functor that assigns to such an  over the formal scheme
over the formal scheme  .
.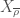 indexed by residual pseudo-representations (semi-simple pseudo-representations over a finite field). Similarly,
indexed by residual pseudo-representations (semi-simple pseudo-representations over a finite field). Similarly,  , each with a map to the corresponding
, each with a map to the corresponding 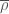 is irreducible,
is irreducible, 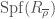 , while
, while 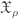 will be
will be 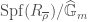 , where
, where  is the universal deformation ring, and
is the universal deformation ring, and 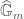 is some formal completion of
is some formal completion of 
 , for all
, for all 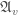 on each
on each  . We can form the product of these sheaves and pull back to get a sheaf
. We can form the product of these sheaves and pull back to get a sheaf 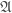 on the global stack
on the global stack 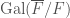 , but all of them were
, but all of them were 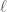 -adic, see the discussion in that post for the explanation behind the terminology). What about complex Galois representations? For instance, since the complex
-adic, see the discussion in that post for the explanation behind the terminology). What about complex Galois representations? For instance, since the complex 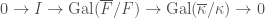
 and is called the inertia subgroup (this can be considered the “local” and also “absolute” version of the exact sequence discussed near the end of
and is called the inertia subgroup (this can be considered the “local” and also “absolute” version of the exact sequence discussed near the end of  of the residue field
of the residue field 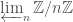 , also known as the profinite integers and denoted
, also known as the profinite integers and denoted 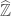 .
. . Since
. Since  of the Weil group and
of the Weil group and  .
.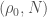 consisting of a representation
consisting of a representation  of the Weil group
of the Weil group 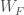 , together with a nilpotent operator
, together with a nilpotent operator  called the monodromy operator, which has to satisfy the property
called the monodromy operator, which has to satisfy the property
 is the valuation of the element of
is the valuation of the element of  we can always associate to it a unique Weil-Deligne representation
we can always associate to it a unique Weil-Deligne representation  where
where 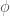 is a lift of Frobenius and
is a lift of Frobenius and  , where
, where  ,
,  being the “tamely ramified” extension of
being the “tamely ramified” extension of 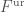 the unramified extension of
the unramified extension of 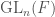 , thus linking two kinds of representations – those of Galois groups like we have discussed here, and those of reductive groups, similar to what was hinted at in
, thus linking two kinds of representations – those of Galois groups like we have discussed here, and those of reductive groups, similar to what was hinted at in 
 being an element of the finite field
being an element of the finite field  in one variable
in one variable  over
over 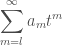
 , and
, and 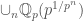 and
and  have the same absolute Galois group! By the fundamental theorem of Galois theory, this means the category formed by their extensions will be equivalent as well.
have the same absolute Galois group! By the fundamental theorem of Galois theory, this means the category formed by their extensions will be equivalent as well.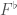 suggestively denote the completion of
suggestively denote the completion of 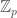 , whose residue field is
, whose residue field is 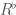 is defined to be the inverse limit
is defined to be the inverse limit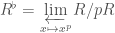
 of
of 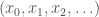 of the quotient
of the quotient  such that
such that  ,
,  , and so on. We want
, and so on. We want 

 , a special name. We will refer to this ring as
, a special name. We will refer to this ring as  . It will make an appearance again later. For now we note that there is going to be a canonical map
. It will make an appearance again later. For now we note that there is going to be a canonical map  .
. . If we know this map, and if we know that it is surjective, then we can recover
. If we know this map, and if we know that it is surjective, then we can recover  !
!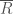 to itself must be surjective. This is actually the origin of the word “perfectoid”; since as above a field for which the Frobenius morphism is bijective is called perfect; hence, requiring it to be surjective is a relaxation of this condition. This condition guarantees that the map
to itself must be surjective. This is actually the origin of the word “perfectoid”; since as above a field for which the Frobenius morphism is bijective is called perfect; hence, requiring it to be surjective is a relaxation of this condition. This condition guarantees that the map 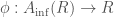 is going to be surjective.
is going to be surjective.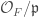 to itself is surjective and such that its valuation is non-discretely valued.
to itself is surjective and such that its valuation is non-discretely valued.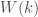 (for example if
(for example if  then
then 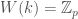 ). Let our residual representation
). Let our residual representation  be the trivial representation, i.e. the group acts as the identity. A lift will be a Galois representation
be the trivial representation, i.e. the group acts as the identity. A lift will be a Galois representation 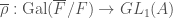 , where
, where ![\displaystyle R _{\overline{\rho}}=W(k)[[\mathrm{Gal}(\overline{F}/F)^{\mathrm{ab,p}}]]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R+_%7B%5Coverline%7B%5Crho%7D%7D%3DW%28k%29%5B%5B%5Cmathrm%7BGal%7D%28%5Coverline%7BF%7D%2FF%29%5E%7B%5Cmathrm%7Bab%2Cp%7D%7D%5D%5D&bg=ffffff&fg=444444&s=0&c=20201002)
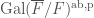 means the pro-p completion of the abelianization of the Galois group
means the pro-p completion of the abelianization of the Galois group ![\displaystyle R_{\overline{\rho}}=W(k)[\mu_{p^{\infty}}(F)][[X_{1},\ldots,X_{[F:\mathbb{Q}]}]]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_%7B%5Coverline%7B%5Crho%7D%7D%3DW%28k%29%5B%5Cmu_%7Bp%5E%7B%5Cinfty%7D%7D%28F%29%5D%5B%5BX_%7B1%7D%2C%5Cldots%2CX_%7B%5BF%3A%5Cmathbb%7BQ%7D%5D%7D%5D%5D&bg=ffffff&fg=444444&s=0&c=20201002)
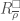 . It is local, and has a unique maximal ideal
. It is local, and has a unique maximal ideal 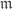 . There is only one tangent space, defined to be the dual of
. There is only one tangent space, defined to be the dual of 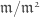 , but this can also be expressed as the set of its dual number-valued points, i.e.
, but this can also be expressed as the set of its dual number-valued points, i.e. ![\mathrm{Hom}(R_{\overline{\rho}}^{\Box},k[\epsilon])](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BHom%7D%28R_%7B%5Coverline%7B%5Crho%7D%7D%5E%7B%5CBox%7D%2Ck%5B%5Cepsilon%5D%29&bg=ffffff&fg=444444&s=0&c=20201002) , which by the definition of the framed deformation functor, is also
, which by the definition of the framed deformation functor, is also ![D_{\overline{\rho}}(k[\epsilon])^{\Box}](https://s0.wp.com/latex.php?latex=D_%7B%5Coverline%7B%5Crho%7D%7D%28k%5B%5Cepsilon%5D%29%5E%7B%5CBox%7D&bg=ffffff&fg=444444&s=0&c=20201002) . Any such deformation must be of the form
. Any such deformation must be of the form
 is some
is some  matrix with coefficients in
matrix with coefficients in  we have
we have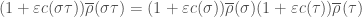
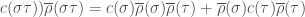
 on the right,
on the right, 
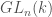 . We call this Galois module
. We call this Galois module  .
. 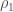 and
and  which give rise to the same deformation of
which give rise to the same deformation of 
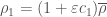 and
and  we obtain
we obtain
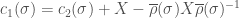
 and
and 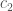 differ by a coboundary. This means that the tangent space of the Galois deformation ring is given by the first Galois cohomology with coefficients in
differ by a coboundary. This means that the tangent space of the Galois deformation ring is given by the first Galois cohomology with coefficients in ![\displaystyle D_{\overline{\rho}}(k[\epsilon])\simeq H^{1}(\mathrm{Gal}(\overline{F}/F),\mathrm{Ad}\overline{\rho})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+D_%7B%5Coverline%7B%5Crho%7D%7D%28k%5B%5Cepsilon%5D%29%5Csimeq+H%5E%7B1%7D%28%5Cmathrm%7BGal%7D%28%5Coverline%7BF%7D%2FF%29%2C%5Cmathrm%7BAd%7D%5Coverline%7B%5Crho%7D%29&bg=ffffff&fg=444444&s=0&c=20201002)
 of
of ![\displaystyle R_{\overline{\rho}}=W(k)[[x_{1},\ldots,x_{g}]]/(f_{1},\ldots,f_{r})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_%7B%5Coverline%7B%5Crho%7D%7D%3DW%28k%29%5B%5Bx_%7B1%7D%2C%5Cldots%2Cx_%7Bg%7D%5D%5D%2F%28f_%7B1%7D%2C%5Cldots%2Cf_%7Br%7D%29&bg=ffffff&fg=444444&s=0&c=20201002)
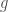 variables, where the number
variables, where the number 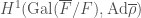 as a
as a  is given by the dimension of
is given by the dimension of  as a
as a 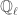 .
. where
where  . The “dual numbers” are defined to be
. The “dual numbers” are defined to be ![\mathbb{R}[x]/(x^{2})](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5Bx%5D%2F%28x%5E%7B2%7D%29&bg=ffffff&fg=444444&s=0&c=20201002) . Its elements are of the form
. Its elements are of the form  where
where  are real numbers. We can consider
are real numbers. We can consider ![\mathbb{R}[x]/(x^{3})](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5Bx%5D%2F%28x%5E%7B3%7D%29&bg=ffffff&fg=444444&s=0&c=20201002) ? We may think of such an element, which is of the form
? We may think of such an element, which is of the form  , to be a position “
, to be a position “ . This is the ring
. This is the ring ![\mathbb{R}[[x]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5B%5Bx%5D%5D&bg=ffffff&fg=444444&s=0&c=20201002) , which is the inverse limit of the rings
, which is the inverse limit of the rings  . Now the ring
. Now the ring  , and modding out by this maximal ideal gives
, and modding out by this maximal ideal gives  is also called a residual representation. Now let
is also called a residual representation. Now let  where
where 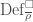 from the category of complete Noetherian local
from the category of complete Noetherian local 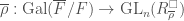 over some ring
over some ring  called the universal framed deformation ring, such that the lifts of
called the universal framed deformation ring, such that the lifts of  . We state that, given an isomorphism between the complex numbers and the p-adic complex numbers we can always construct a map
. We state that, given an isomorphism between the complex numbers and the p-adic complex numbers we can always construct a map  from the preceding map.
from the preceding map. acts on Hecke eigenforms (which say we want to match up with the Galois representations, to show that these Galois representations come from them) and therefore have associated systems of eigenvalues. It is known that any such system of eigenvalues comes from some Hecke eigenform.
acts on Hecke eigenforms (which say we want to match up with the Galois representations, to show that these Galois representations come from them) and therefore have associated systems of eigenvalues. It is known that any such system of eigenvalues comes from some Hecke eigenform.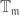 , corresponding to only the modular forms that are expected to give rise to the Galois representations we are considering (the Eichler-Shimura theorem gives relations between the Fourier coefficients of the Hecke eigenform and the form of the characteristic polynomial of the Frobenius under the Galois representation, restricting it). On the other hand, these systems of eigenvalues corresponds to maps
, corresponding to only the modular forms that are expected to give rise to the Galois representations we are considering (the Eichler-Shimura theorem gives relations between the Fourier coefficients of the Hecke eigenform and the form of the characteristic polynomial of the Frobenius under the Galois representation, restricting it). On the other hand, these systems of eigenvalues corresponds to maps  .
. , then these two sets of maps to
, then these two sets of maps to  is one of the most important objects of study in mathematics. However the direct study of this group is very difficult; for instance it is an infinite group, and we know very little about it. To make it easier for us, we will often instead study representations of this group – i.e. group homomorphisms to the group
is one of the most important objects of study in mathematics. However the direct study of this group is very difficult; for instance it is an infinite group, and we know very little about it. To make it easier for us, we will often instead study representations of this group – i.e. group homomorphisms to the group 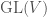 of linear transformations of some vector space
of linear transformations of some vector space  , the group of
, the group of  to
to 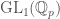 , which also happens to just be the multiplicative group
, which also happens to just be the multiplicative group 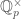 . Let us explain how to obtain this Galois representation.
. Let us explain how to obtain this Galois representation.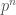 -th root of unity
-th root of unity 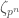 . Any element
. Any element  , i.e. an element of
, i.e. an element of  . We now define the
. We now define the  to be the map from
to be the map from 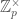 which sends the element
which sends the element  , so the inverse limit is going to be isomorphic to
, so the inverse limit is going to be isomorphic to  . This is not a vector space, since
. This is not a vector space, since 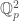 , which is a vector space. Therefore we get a Galois representation, i.e. a homomorphism from
, which is a vector space. Therefore we get a Galois representation, i.e. a homomorphism from  . This construction also works for abelian varieties – higher dimensional analogues of elliptic curves – except that the Tate module is now
. This construction also works for abelian varieties – higher dimensional analogues of elliptic curves – except that the Tate module is now 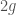 -dimensional, where
-dimensional, where  . These etale cohomology groups are somewhat confusingly denoted
. These etale cohomology groups are somewhat confusingly denoted  – note that they are not the etale cohomology of
– note that they are not the etale cohomology of  . We say that the first
. We say that the first 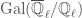 instead. In this case we might as well just have replaced
instead. In this case we might as well just have replaced  to
to  . This is the reason for the terminology “
. This is the reason for the terminology “ has an Euler product. Together with the meromorphic continuation and the functional equation, these are the important properties of the Riemann zeta function, which L-functions are supposed to be generalizations of. Hecke’s study was inspired by the work of Bernhard Riemann on the zeta function.
has an Euler product. Together with the meromorphic continuation and the functional equation, these are the important properties of the Riemann zeta function, which L-functions are supposed to be generalizations of. Hecke’s study was inspired by the work of Bernhard Riemann on the zeta function. , for
, for  can also be expressed as
can also be expressed as  where
where 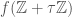 is holomorphic as a function on the upper half-plane
is holomorphic as a function on the upper half-plane
 for some nonzero complex number
for some nonzero complex number  , and
, and 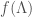 of weight
of weight 
 runs over the sublattices of
runs over the sublattices of  be a modular form of weight
be a modular form of weight  , where we have adopted the convention
, where we have adopted the convention 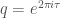 which is common in the theory of modular forms (hence this Fourier expansion is also known as a
which is common in the theory of modular forms (hence this Fourier expansion is also known as a 
 when
when  sublattices of index
sublattices of index 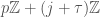 for
for  ranging from
ranging from 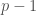 , and another one given by
, and another one given by  . Let us split up the Hecke operators as follows:
. Let us split up the Hecke operators as follows:
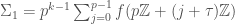 and
and 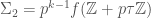 . Let us focus on the former first. We have
. Let us focus on the former first. We have
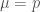 , we have
, we have
 , so we expand them as a Fourier series
, so we expand them as a Fourier series

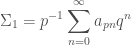
 . We have
. We have
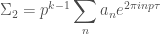

 and
and 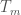 and
and  commute with each other. They preserve the weight of a modular form, and take cusp forms to cusp forms (this can be seen via their effect on the Fourier series). We can also define Hecke operators for modular forms with level structure, but it is more complicated and has some subtleties when for the Hecke operator
commute with each other. They preserve the weight of a modular form, and take cusp forms to cusp forms (this can be seen via their effect on the Fourier series). We can also define Hecke operators for modular forms with level structure, but it is more complicated and has some subtleties when for the Hecke operator  is equal to
is equal to  for
for  and
and  for
for 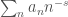 . This L-series will have an Euler product if and only if the coefficients
. This L-series will have an Euler product if and only if the coefficients  for
for  for
for  and another operator denoted
and another operator denoted  . These and more on Hecke operators, such as other ways to define them with double coset operators or Hecke correspondences will hopefully be discussed in future posts.
. These and more on Hecke operators, such as other ways to define them with double coset operators or Hecke correspondences will hopefully be discussed in future posts.  , where
, where 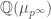 is the extension of the rational numbers
is the extension of the rational numbers  .
. and a group isomorphic to
and a group isomorphic to 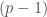 -th roots of unity. Let
-th roots of unity. Let ![\mathbb{Z}_{p}[[\Gamma]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D_%7Bp%7D%5B%5B%5CGamma%5D%5D&bg=ffffff&fg=444444&s=0&c=20201002) , which also happens to be isomorphic to the power series ring
, which also happens to be isomorphic to the power series ring ![\mathbb{Z}_{p}[[T]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D_%7Bp%7D%5B%5BT%5D%5D&bg=ffffff&fg=444444&s=0&c=20201002) .
. and gives an element of
and gives an element of 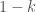 shows up in the constant term in the Fourier expansion of the Eisenstein series
shows up in the constant term in the Fourier expansion of the Eisenstein series 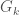 :
:
 ,
,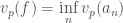

 .
. , which is isomorphic to the product of
, which is isomorphic to the product of 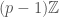 . Here is where measures come in – this space of weights can be identified with characters of
. Here is where measures come in – this space of weights can be identified with characters of  and being such a function, it is an input for a measure!
and being such a function, it is an input for a measure!
