The branch of physics now known as statistical mechanics started out as thermodynamics, the study of heat and related concepts. The relation of thermodynamics to the rest of physics, i.e. the relation of heat and motion, was studied by scientists like James Prescott Joule in the 19th century. Due to their efforts, we have the idea that what they used to refer to as “heat” is a form of energy which is transferred from one object to another, manifesting in ways other than the bulk motion of the objects (in particular, as a change in the “internal energy” of the objects involved) .
Energy, a concept that was already associated to the motion of objects (see also Lagrangians and Hamiltonians), can be transferred from one object to another, or one system to another, and in the case of heat, this transfer involves the concept of temperature. Temperature is what we measure on a thermometer, and when we say something is “hot” or “cold”, we are usually referring to its temperature.
The way by which temperature dictates the direction in which heat is transferred is summarized in the second law of thermodynamics (here we give one of its many equivalent statements):
Heat flows from a hotter object to a colder one.
This process of transfer of heat will continue, decreasing the internal energy of the hotter object and increasing the internal energy of the cooler one, until the two objects have equal temperatures, in which case we say that they are in thermal equilibrium.
But if heat is a transfer of energy, and energy is associated to motion, then what was it, exactly, that was moving (or had the capacity to cause something to move)? What is this “internal energy?” For us, who have been taught about atoms and molecules since childhood, the answer might come rather easily. Internal energy is the energy that comes from the motion of the atoms and molecules that comprise the object. But for the scientists who were developing the subject during the 19th century, the concept of atoms and molecules was still in its very early stages, with many of them facing severe criticism for adopting ideas that at the time were still not completely verified.
Still, these scientists continued to take the point of view that the subject of thermodynamics was just the same physics that had already been applied to, say, the motion of cannonballs and pendulums and other objects, except that now they had to be applied to a very large quantity of very small particles (quantum mechanics would later have much to contribute also, but even before the introduction of that theory the concept of atoms and molecules was already starting to become very fruitful in thermodynamics).
Now we have an explanation for what internal energy is in terms of the motion of the particles that make up an object. But what about temperature? It is possible to explain temperature (and therefore the laws that decide the direction of the transfer of heat) using more “basic” concepts such as Newton’s laws of motion, like we have done for the internal energy?
It was the revolutionary ideas of Ludwig Boltzmann that provided the solution. It indeed involved a more “basic” concept, but not one we would usually think of as belonging to the realm of physics or the study of motion. The idea of Boltzmann was to relate temperature to the concepts of information, probability, and statistics, via the notion of entropy. We may therefore think of this era as the time when “thermodynamics” became “statistical mechanics”.
In order to discuss the idea of entropy, for a moment we step away from physics, and discuss instead cards. It is not cards themselves that we are interested in, but information. Entropy is really about information, which is why it also shows up, for instance, when discussing computer passwords. Cards will give us a simple but concrete way to discuss information.
Consider now, therefore, a deck of 52 ordinary playing cards. A hand, of course, consists of five cards. Using the rules of combinatorics, we can find that there are 2,598,960 different hands (combinations of 52 different playing cards taken five at a time, in any order). In the game of poker, there are certain special combinations, the rarest (and highest-ranking) of which is called the “royal flush”. There are only four possible ways to get a royal flush (one for each suit). In contrast, the most common kind of hand is one which has no special combination (sometimes called “no pair”), and there are 1,302,540 different combinations which fit this description.
Now suppose the deck is shuffled and we are dealt a hand. The shuffling process is not entirely random (not in the way that quantum mechanics is), but there are so many things going on that it is near-impossible for us to follow and determine what kind of hand we are going to get. The most we can do is make use of what we know about probability and statistics. We know that it is more likely for us to obtain a no pair rather than a royal flush, simply because there are so many more combinations that are considered a no pair than there are combinations that are considered a royal flush. There are no laws of physics involved in making this prediction; there is only the intuitive idea that an event with more ways of happening is more likely to happen compared to an event with less ways of happening, in the absence of any more information regarding the system.
We now go back to physics. Let us consider a system made up of a very large number of particles. The state of a single particle is specified by its position and momentum, and the state of the entire system is specified by the position and momentum of every one of its particles. This state is almost impossible for us to determine, because there are simply too many particles to keep track of.
However, we may be able to determine properties of the system without having to look at every single particle. Such properties may involve the total energy, pressure, volume, and so on. These properties determine the “macrostate” of a system. The “true” state that may only be specified by the position and momentum of every single particle is called the “microstate” of the system. There may be several different microstates that correspond to a single macrostate, just like there are four different combinations that correspond to a royal flush, or 1,302,540 different combinations that correspond to a no pair.
Let the system be in a certain macrostate, and let the number of microstates that correspond to this macrostate be denoted by 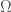 . The entropy of the system is then defined as
. The entropy of the system is then defined as
 .
.
where  is a constant known as Boltzmann’s constant. We may think of this constant and the logarithm as merely convenient ways (in terms of calculation, and in terms of making contact with older ideas in thermodynamics) to express the idea that the higher the number of microstates, the higher the entropy.
is a constant known as Boltzmann’s constant. We may think of this constant and the logarithm as merely convenient ways (in terms of calculation, and in terms of making contact with older ideas in thermodynamics) to express the idea that the higher the number of microstates, the higher the entropy.
Now even though the system may not seem to be changing, imperceptible to us, there may be many things that happen on a microscopic level. Molecules may be moving around in many directions, in motions that are too difficult for us to keep track of, not only because the particles are very small but also because there are just too many of them. This is analogous to the shuffling of cards. All that we have at our disposal are the tools of probability and statistics. Hence the term, “statistical mechanics“.
What have we learned from the example of the shuffling of cards? Even though we could not keep track of things and determine results, we could still make predictions. And the predictions we made were simply of the nature that an event with more ways of happening was more likely to happen than an even with less ways of happening.
Therefore, we have the following restatement of the second law of thermodynamics:
The entropy of a closed system never decreases.
This simply reflects the idea that under these processes we cannot keep track of, the system is more likely to adopt a configuration with more ways of happening, compared to one with less ways of happening. In other words,it will be in a macrostate that will have more microstates. Microscopically, it may happen that “miraculously” the entropy increases; but given how many particles there are, and how many processes happen, this is extremely unlikely to be a sustained phenomenon, and macroscopically, the second law of thermodynamics is always satisfied. This is like obtaining a royal flush on one deal of cards; but if we are going to reshuffle multiple times, it is unlikely that we keep getting royal flushes for a sustained period of time.
The “closed system” requirement is there to ensure that the system is “left to its own devices” so to speak, or that there is no “outside interference”.
Considering that the entirety of the universe is an example of a “closed system” (there is nothing outside of it, since by definition the universe means the collection of everything that exists), the second law of thermodynamics has some interesting (perhaps disturbing, to some people) implications. What we usually consider to be an “ordered” configuration is very specific; for example, a room is only in order when all of the furniture is upright, all the trash is in the wastebasket, and so on. There are fewer such configurations compared to the “disordered” ones, since there are so many ways in which the furniture can be “not upright”, and so many ways in which the trash may be outside of the wastebasket, etc. In other words, disordered configurations have higher entropy. All of these things considered, what the second law of thermodynamics implies is that the entropy of the universe is ever increasing, moving toward an increasing state of disorder, away from the delicate state of order that we now enjoy.
We now want to derive the “macroscopic” from the “microscopic”. We want to connect the “microscopic” concept of entropy to the “macroscopic” concept of temperature. We do this by defining “temperature” as the following relationship between the entropy and the energy (in this case the internal energy, as the system may have other kinds of energy, for example arising from its motion in bulk):
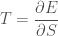
Although we will not discuss the specifics in this post, we make the following claim – the entropy of the system is at its maximum when the system is in thermal equilibrium. Or perhaps more properly, the state of “thermal equilibrium” may be defined as the macrostate which has the most amount of microstates corresponding to it. This in turn explains why heat flows from a hotter object to a cooler one.
We have now discussed some of the most basic concepts in thermodynamics and statistical mechanics. We now briefly discuss certain technical and calculational aspects of the theory. Aside from making the theory more concrete, this is important also because there are many analogies to be made outside of thermodynamics and statistical mechanics. For example, in the Feynman path integral formulation of quantum field theory (see Some Basics of Relativistic Quantum Field Theory) we calculate correlation functions, which mathematically have a form very similar to some of the quantities that we will discuss.
In modern formulations of statistical mechanics, a central role is played by the partition function 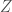 , which is defined as
, which is defined as

where 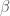 , often simply referred to as the “thermodynamic beta”, is defined as
, often simply referred to as the “thermodynamic beta”, is defined as
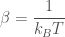 .
.
The partition function is a very convenient way to package information about the system we are studying, and many quantities of interest can be obtained from it. One of the most important ones is the probability 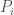 for the system to be in a macrostate with energy
for the system to be in a macrostate with energy  :
:
 .
.
Knowing this formula for the probabilities of certain macrostates allows us to derive the formulas for expectation values of quantities that may be of interest to us, such as the average energy of the system:
 .
.
After some manipulation we may find that the expectation value of the energy is also equal to the following more compact expression:
 .
.
Another familiar quantity that we can obtain from the partition function is the entropy of the system:
 .
.
There are various other quantities that can be obtained from the partition function, such as the variance of the energy (or energy fluctuations), the heat capacity, and the so-called Helmholtz free energy. We note that for “continuous” systems, expressions involving sums are replaced by expressions involving integrals. Also, for quantum mechanical systems, there are some modifications, as well as for systems which exchange particles with the environment.
The development of statistical mechanics, and the introduction of the concept of entropy, is perhaps a rather understated revolution in physics. Before Boltzmann’s redefinition of these concepts, physics was thought of as studying only motion, in the classical sense of Newton and his contemporaries. Information has since then taken just as central a role in modern physics as motion.
The mathematician and engineer Claude Elwood Shannon further modernized the notion of entropy by applying it to systems we would not have ordinarily thought of as part of physics, for example the bits on a computer. According to some accounts, Shannon was studying a certain quantity he wanted to name “information”; however, the physicist and mathematician John von Neumann told him that a version of his concept had already been developed before in physics, and was called “entropy”. With Neumann’s encouragement, Shannon adopted the name, symbolically unifying subjects formerly thought of as separate.
Information theory, the subject which Shannon founded, has together with quantum mechanics led to quantum information theory, which not only has many potential applications in technology but also is one of the methods by which we attempt to figure out deep questions regarding the universe.
Another way in which the concept of entropy is involved in modern issues in physics is in the concept of entropic gravity, where gravity, as expressed in Einstein’s general theory of relativity, is derived from more fundamental concepts similar to how the simple statistical concept of entropy gives rise to something that manifests macroscopically as a law of physics. Another part of modern physics where information, quantum mechanics, and general relativity meet is the open problem called the black hole information paradox, which concerns the way in which black holes seemingly do not conserve information, and is a point of contention among many physicists even today.
Finally, we mention another very interesting aspect of statistical mechanics, perhaps, on the surface, a little more mundane compared to what we have mentioned on the preceding paragraphs, but not the slightest bit less interesting – phase transitions. Phase transitions are “abrupt” changes in the property of an object brought about by some seemingly continuous process, like, for example, the freezing of water into ice. We “cool” water, taking away heat from it by some process, and for a long time it seems that nothing happens except that the water becomes colder and colder, but at some point it freezes – an abrupt change, even though we have done just the same thing we did to it before. What really happens, microscopically, is that the molecules have arranged themselves into a some sort of structure, and the material loses some of symmetry (the “disordered” molecules of water were more symmetric than the “ordered” molecules in ice) – a process known as symmetry breaking. Phase transitions and symmetry breaking are ubiquitous in the sciences, and have applications from studying magnets to tackling the problem of why we have observed so much more matter compared to antimatter.
References:
Thermodynamics on Wikipedia
Statistical Mechanics on Wikipedia
Entropy on Wikipedia
Partition Function on Wikipedia
Entropy in Thermodynamics and Information Theory on Wikipedia
Quantum Information on Wikipedia
Black Hole Information Paradox on Wikipedia
Phase Transition on Wikipedia
Symmetry Breaking on Wikipedia
It From Bit – Entropic Gravity for Pedestrians on Science 2.0
Black Hole Information Paradox: An Introduction on Of Particular Significance
Thermal Physics by Charles Kittel and Herbert Kroemer
Fundamentals of Statistical and Thermal Physics by Frederick Reif
A Modern Course in Statistical Physics by Linda Reichl


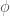
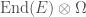
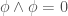








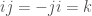
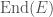

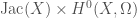
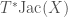



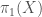
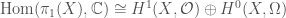

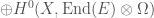
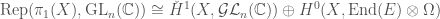
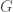 we’re interested in, to the group of linear transformations of some vector space. If the vector space has some finite dimension
we’re interested in, to the group of linear transformations of some vector space. If the vector space has some finite dimension 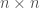 matrices with nonzero determinant, also known as
matrices with nonzero determinant, also known as 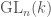 (
( has components
has components  indexed by
indexed by  has values
has values 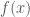 indexed by
indexed by  . If we are working over uncountable things, instead of summation we may use integration.
. If we are working over uncountable things, instead of summation we may use integration. (under addition). We want to use representation theory to study this group. For our purposes we want the square-integrable functions on some quotient of
(under addition). We want to use representation theory to study this group. For our purposes we want the square-integrable functions on some quotient of  of
of  .
. . The quotient
. The quotient  is the circle, and functions on it are periodic functions.
is the circle, and functions on it are periodic functions. (the complex numbers) where a real number
(the complex numbers) where a real number  by
by  , for
, for 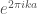 where
where  or
or  (or
(or 

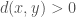 for all
for all  ; equality holds if and only if
; equality holds if and only if  .
.  for all
for all  , for all
, for all  .
.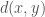 is often called the distance between
is often called the distance between  in the metric
in the metric 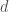 . Given
. Given  , consider the set
, consider the set
 . It is called the
. It is called the  when no confusion will arise.
when no confusion will arise.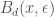 , for
, for  and
and 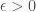 , is a basis for a topology on
, is a basis for a topology on  is given by the ordinary “distance formula”:
is given by the ordinary “distance formula”:
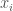 and
and  are their respective coordinates.
are their respective coordinates. if
if 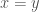
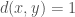 if
if  .
.
 (read “norm of
(read “norm of 
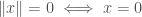

 (triangle inequality)
(triangle inequality) is any scalar.
is any scalar.


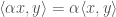

 ,
, 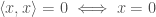
 and
and 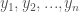 in some basis. Then we can set
in some basis. Then we can set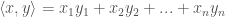
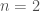 , so that we are dealing with vectors (which we can now think of as quantities with magnitude and direction) in the plane. A unit vector
, so that we are dealing with vectors (which we can now think of as quantities with magnitude and direction) in the plane. A unit vector  , while a unit vector
, while a unit vector 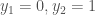 . These two vectors are perpendicular, or orthogonal. Computing the inner product we discussed earlier, we have
. These two vectors are perpendicular, or orthogonal. Computing the inner product we discussed earlier, we have .
.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002) . We set our inner product to be
. We set our inner product to be .
. and
and  . We say that these functions are “orthogonal”, but it is hard to imagine in what way. But if we take the inner product, we will see that
. We say that these functions are “orthogonal”, but it is hard to imagine in what way. But if we take the inner product, we will see that .
. and
and 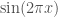 are orthogonal. Similarly, we have
are orthogonal. Similarly, we have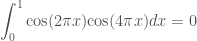
 are also orthogonal. We have discussed this in more detail in
are also orthogonal. We have discussed this in more detail in 
 -dimensional Euclidean space is the plane
-dimensional Euclidean space is the plane 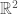 , and so on. Obviously, Euclidean space itself is a manifold, but we want to look at more interesting examples, i.e. spaces that “locally” look like Euclidean space but “globally” are very different from it.
, and so on. Obviously, Euclidean space itself is a manifold, but we want to look at more interesting examples, i.e. spaces that “locally” look like Euclidean space but “globally” are very different from it. from the open subsets
from the open subsets 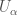 covering
covering  is a differentiable function on
is a differentiable function on 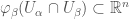 .
.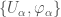 is called a chart, and the collection of all these charts that cover the manifold is called an atlas. The map
is called a chart, and the collection of all these charts that cover the manifold is called an atlas. The map  is called a transition map.
is called a transition map. from
from  is homeomorphic to the product space
is homeomorphic to the product space  , where
, where  is the fiber, defined as
is the fiber, defined as 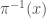 for any point
for any point  be the ring of real-valued differentiable functions defined in a neighborhood of a point
be the ring of real-valued differentiable functions defined in a neighborhood of a point  in a differentiable manifold
in a differentiable manifold  , to be the vector space of
, to be the vector space of 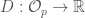 satisfying Leibniz’s rule
satisfying Leibniz’s rule  . Any such derivation
. Any such derivation  can be written in the following form:
can be written in the following form: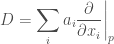
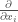 is a basis for the real tangent space at
is a basis for the real tangent space at 
 , and its tangent space at the point
, and its tangent space at the point  . One of the tangent vectors,
. One of the tangent vectors,  is often used to define the tangent vector, although that is not the approach we have given here (it may be found in the references, and is closely related to the definition we have given).
is often used to define the tangent vector, although that is not the approach we have given here (it may be found in the references, and is closely related to the definition we have given). .
.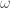 ) is given by
) is given by
 is the position and
is the position and 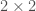 matrices which form a group (see
matrices which form a group (see  (together with other matrices which express reflections, they form a bigger group that we call the orthogonal group in
(together with other matrices which express reflections, they form a bigger group that we call the orthogonal group in  ).
).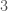 -dimensional space. As we will soon see, notations in
-dimensional space. As we will soon see, notations in  .
.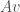 , for a matrix
, for a matrix  , to be orthogonal. Alternatively, we may require, for the matrix
, to be orthogonal. Alternatively, we may require, for the matrix 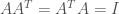
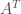 is the transpose of
is the transpose of 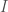 is the identity matrix. The word “special” denotes that our matrices must have determinant equal to
is the identity matrix. The word “special” denotes that our matrices must have determinant equal to 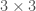 orthogonal matrices whose determinant is equal to
orthogonal matrices whose determinant is equal to 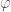 , is expressed as a counterclockwise rotation about the
, is expressed as a counterclockwise rotation about the  , is a counterclockwise rotation about an
, is a counterclockwise rotation about an  , is expressed as a counterclockwise rotation about a
, is expressed as a counterclockwise rotation about a  .
.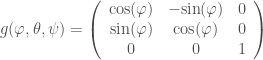 .
. of
of  may not always be equal to the product
may not always be equal to the product  . One can check this explicitly, or simply consider rotating an object along different axes; for example, rotating an object first counterclockwise by 90 degrees along the
. One can check this explicitly, or simply consider rotating an object along different axes; for example, rotating an object first counterclockwise by 90 degrees along the 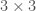 orthogonal matrices. Now we discuss another way of expressing the same concept, but using “unitary”, instead of orthogonal, matrices. However, first we must revisit rotations in
orthogonal matrices. Now we discuss another way of expressing the same concept, but using “unitary”, instead of orthogonal, matrices. However, first we must revisit rotations in  . It is the group formed by the complex numbers with magnitude equal to
. It is the group formed by the complex numbers with magnitude equal to  , where
, where  , which satisfies
, which satisfies 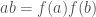 for
for  are often referred to as the circle group.
are often referred to as the circle group.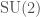 , the special unitary group in dimension
, the special unitary group in dimension 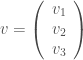 .
.
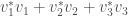
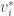 denotes the complex conjugate of the complex number
denotes the complex conjugate of the complex number 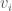 . This is the square of the analogous notion of “magnitude” for vectors with complex number entries.
. This is the square of the analogous notion of “magnitude” for vectors with complex number entries.
 is the Hermitian conjugate of
is the Hermitian conjugate of  – dimensional sphere, or what we call a
– dimensional sphere, or what we call a  . It is a manifold which can be described using the concepts of projective geometry (see
. It is a manifold which can be described using the concepts of projective geometry (see  meters, a constant quantity which is known as the Planck length.
meters, a constant quantity which is known as the Planck length.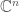 , in the same way that ordinary differentiable manifolds locally look like
, in the same way that ordinary differentiable manifolds locally look like  , mimicking the usual multiplication by the imaginary unit
, mimicking the usual multiplication by the imaginary unit 

 , is the same as another version of string theory, called Type IIB string theory, on a spacetime with extra dimensions compactified onto another Calabi-Yau manifold
, is the same as another version of string theory, called Type IIB string theory, on a spacetime with extra dimensions compactified onto another Calabi-Yau manifold 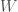 , which is “mirror” to the Calabi-Yau manifold
, which is “mirror” to the Calabi-Yau manifold  be a
be a  -dimensional symplectic manifold with
-dimensional symplectic manifold with  and
and  (or a suitably enlarged one) is equivalent to the derived category of coherent sheaves on a complex algebraic variety
(or a suitably enlarged one) is equivalent to the derived category of coherent sheaves on a complex algebraic variety 
{kind=link}